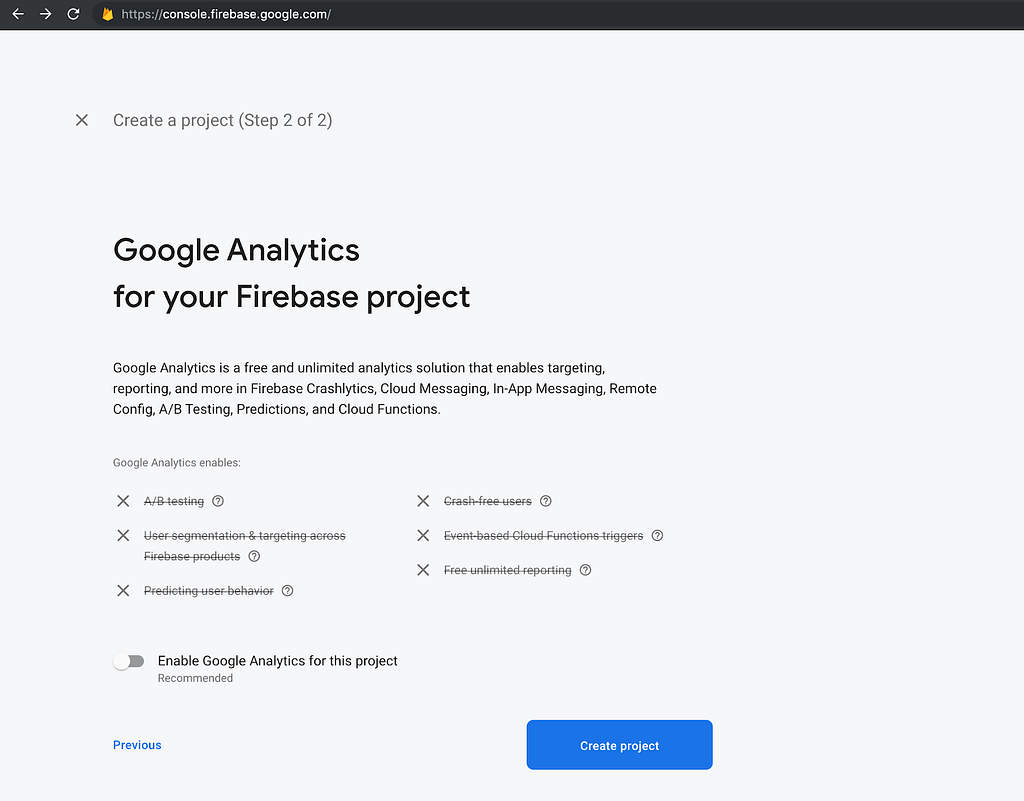
$ flutter channel dev $ flutter upgrade $ flutter config — enable-web
$ flutter create .
$ npm install -g firebase-tools
$ firebase login
$ firebase logout
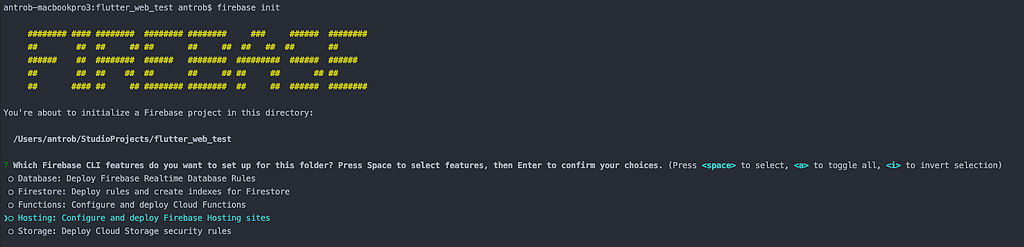
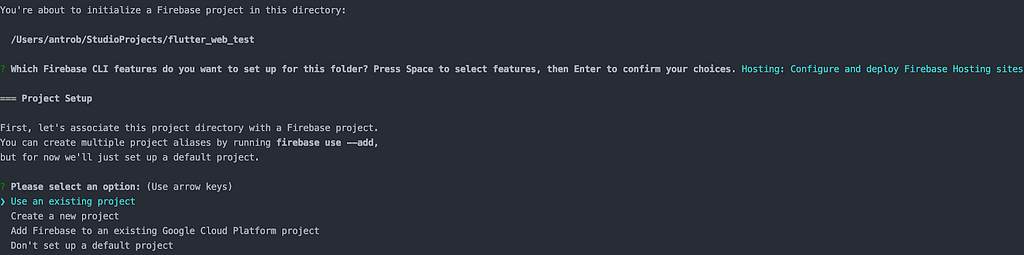
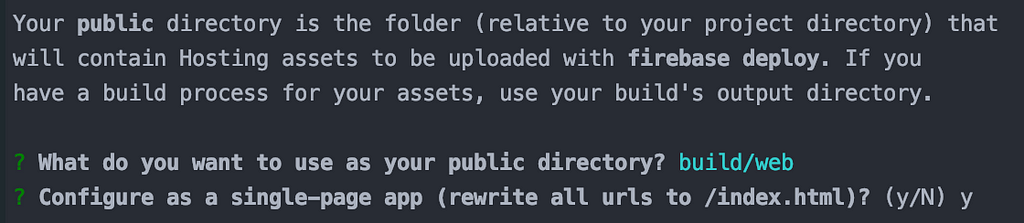
$ firebase init
$ flutter build web
$ flutter channel beta * dev master stable $ ~ $ flutter devices 2 connected devices:
Chrome • chrome • web-javascript • Google Chrome 78.0.3904.87 Web Server • web-server • web-javascript • Flutter Tools
$ firebase deploy
pip install transformers
{ "attention_probs_dropout_prob": 0.1, "hidden_act": "gelu", "hidden_dropout_prob": 0.1, "hidden_size": 768, "initializer_range": 0.02, "intermediate_size": 3072, "max_position_embeddings": 512, "num_attention_heads": 12, "num_hidden_layers": 12, "type_vocab_size": 2, "vocab_size": 28996 }
from transformers import (TFBertModel, BertTokenizer, TFGPT2Model, GPT2Tokenizer) bert_model = TFBertModel.from_pretrained("bert-base-cased") # Automatically loads the config bert_tokenizer = BertTokenizer.from_pretrained("bert-base-cased") gpt2_model = TFGPT2Model.from_pretrained("gpt2") # Automatically loads the config gpt2_tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
import tensorflow_datasets from transformers import glue_convert_examples_to_features data = tensorflow_datasets.load("glue/mrpc") train_dataset = data["train"] validation_dataset = data["validation"] train_dataset = glue_convert_examples_to_features(train_dataset, bert_tokenizer, 128, 'mrpc') validation_dataset = glue_convert_examples_to_features(validation_dataset, bert_tokenizer, 128, 'mrpc') train_dataset = train_dataset.shuffle(100).batch(32).repeat(2) validation_dataset = validation_dataset.batch(64)
optimizer = tf.keras.optimizers.Adam(learning_rate=3e-5, epsilon=1e-08, clipnorm=1.0) loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True) metric = tf.keras.metrics.SparseCategoricalAccuracy('accuracy') bert_model.compile(optimizer=optimizer, loss=loss, metrics=[metric]) bert_history = bert_model.fit( bert_train_dataset, epochs=2, steps_per_epoch=115, validation_data=bert_validation_dataset, validation_steps=7 )
model = TFBertForSequenceClassification.from_pretrained("bert-base-cased") tokenizer = BertTokenizer.from_pretrained("bert-base-cased") data = tensorflow_datasets.load("glue/mrpc") train_dataset = data["train"] train_dataset = glue_convert_examples_to_features(train_dataset, tokenizer, 128, 'mrpc') optimizer = tf.keras.optimizers.Adam(learning_rate=3e-5, epsilon=1e-08, clipnorm=1.0) loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True) metric = tf.keras.metrics.SparseCategoricalAccuracy('accuracy') model.compile(optimizer=optimizer, loss=loss, metrics=[metric]) model.fit(train_dataset, epochs=3)
model = TFDistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased") tokenizer = DistilbertTokenizer.from_pretrained("distilbert-base-uncased")
"Non si tratta di me che cerco di risolvere un problema. Sono io che cerco di imparare qualcosa di nuovo o che osservo qualcun altro mentre scrive codice." - Uno spettatore
"Mi piace osservare le varie fasi del ragionamento del programmatore e il fatto che commetta errori. Molte persone apportano troppe modifiche e quindi finisci per ritrovarti solo un programma fluido e senza errori. Non cercano né consultano nulla e per me non è realistico. Quindi penso che sia più divertente e più facile seguire molti video in live streaming o i relativi arcade video, in cui sono ancora presenti gli errori." - Uno spettatore
"Faccio domande su cose che non conosco o quando potrei implementare una cosa oppure un'altra." - Uno streamer