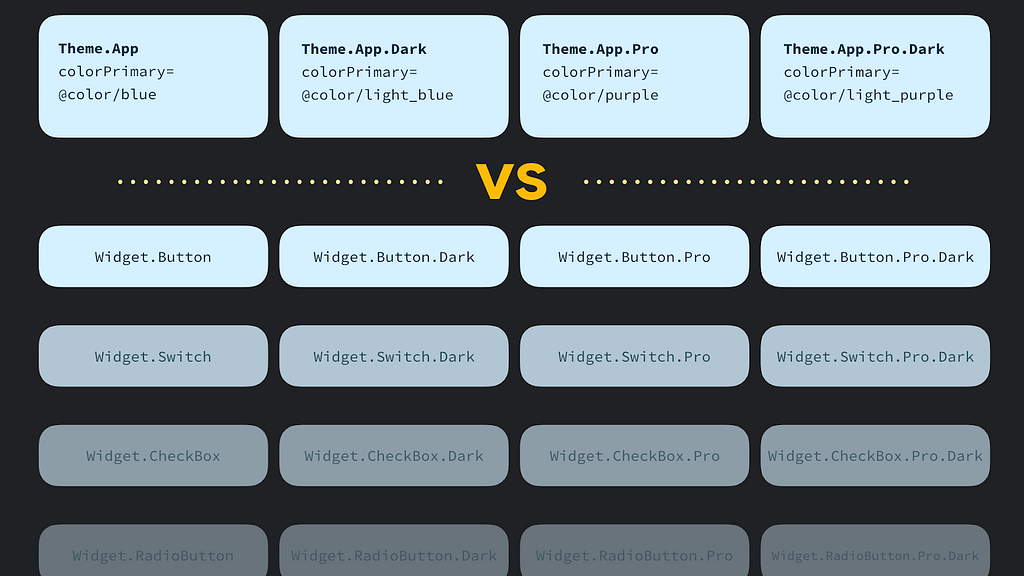
Gli stili sono una raccolta di attributi di visualizzazione; specifici per un singolo tipo di widget
<!-- Copyright 2019 Google LLC. SPDX-License-Identifier: Apache-2.0 --> <style name="Widget.Plaid.Button.InlineAction" parent="…"> <item name="android:gravity">center_horizontal</item> <item name="android:textAppearance">@style/TextAppearance.CommentAuthor</item> <item name="android:drawablePadding">@dimen/spacing_micro</item> </style>
<!-- Copyright 2019 Google LLC. SPDX-License-Identifier: Apache-2.0 --> <Button … android:gravity="center_horizontal" android:textAppearance="@style/TextAppearance.CommentAuthor" android:drawablePadding="@dimen/spacing_micro"/>
<!-- Copyright 2019 Google LLC. SPDX-License-Identifier: Apache-2.0 --> <Button … style="@style/Widget.Plaid.Button.InlineAction"/>
<!-- Copyright 2019 Google LLC. SPDX-License-Identifier: Apache-2.0 --> <style name="Theme.Plaid" parent="…"> <item name="colorPrimary">@color/teal_500</item> <item name="colorSecondary">@color/pink_200</item> <item name="android:windowBackground">@color/white</item> </style>
I temi sono una raccolta di risorse denominate, utili in generale in un'app
/* Copyright 2019 Google LLC. SPDX-License-Identifier: Apache-2.0 */ interface ColorPalette { @ColorInt val colorPrimary @ColorInt val colorSecondary } class MyView(colors: ColorPalette) { fab.backgroundTint = colors.colorPrimary }
/* Copyright 2019 Google LLC. SPDX-License-Identifier: Apache-2.0 */ val lightPalette = object : ColorPalette { … } val darkPalette = object : ColorPalette { … } val view = MyView(if (isDarkTheme) darkPalette else lightPalette)
<!-- Copyright 2019 Google LLC. SPDX-License-Identifier: Apache-2.0 --> <!-- AndroidManifest.xml --> <application … android:theme="@style/Theme.Plaid"> <activity … android:theme="@style/Theme.Plaid.About"/> <!-- layout/foo.xml --> <ConstraintLayout … android:theme="@style/Theme.Plaid.Foo">
<!-- Copyright 2019 Google LLC. SPDX-License-Identifier: Apache-2.0 --> <ViewGroup … android:background="?attr/colorSurface">
Usa la sintassi ?attr/themeAttributeName per eseguire una query al tema per il valore di questo attributo semantico
<!-- Copyright 2019 Google LLC. SPDX-License-Identifier: Apache-2.0 --> <ViewGroup … android:theme="@style/Theme.App.SomeTheme"> <! - SomeTheme also applies to all child views. --> </ViewGroup>
typealias TeardownLogic = () -> Unit fun onCancel(teardown : TeardownLogic){ }
private typealias OnDoggoClick = (dog: Pet.GoodDoggo) -> Unit val onClick: OnDoggoClick
typealias TeardownLogic = () -> Unit //or typealias TeardownLogic = (exception: Exception) -> Unit
fun onCancel(teardown : TeardownLogic){ // can’t easily see what information we have // available in TeardownLogic }
typealias Doggos = List<Pet.GoodDoggo>
fun train(dogs: Doggos){ … }
Chiediti se l'uso di un typealias rende il tuo codice più comprensibile.
typealias AVD = AnimatedVectorDrawable
import android.graphics.drawable.AnimatedVectorDrawable as AVD
import io.plaidapp.R as appR
import io.plaidapp.about.R
expect annotation class Test
actual typealias Test = org.junit.Test
// Kotlin typealias Doggos = List<Pet.GoodDoggo> fun train(dogs: Doggos) { … }
// Decompiled Java code public static final void train(@NotNull List dogs) { … }
I typealias non introducono nuovi tipi.
fun play(dogId: Long)
typealias DogId = Long
fun pet(dogId: DogId) { … }
fun usage() { val cat = Cat(1L) pet(cat.catId) // compiles }
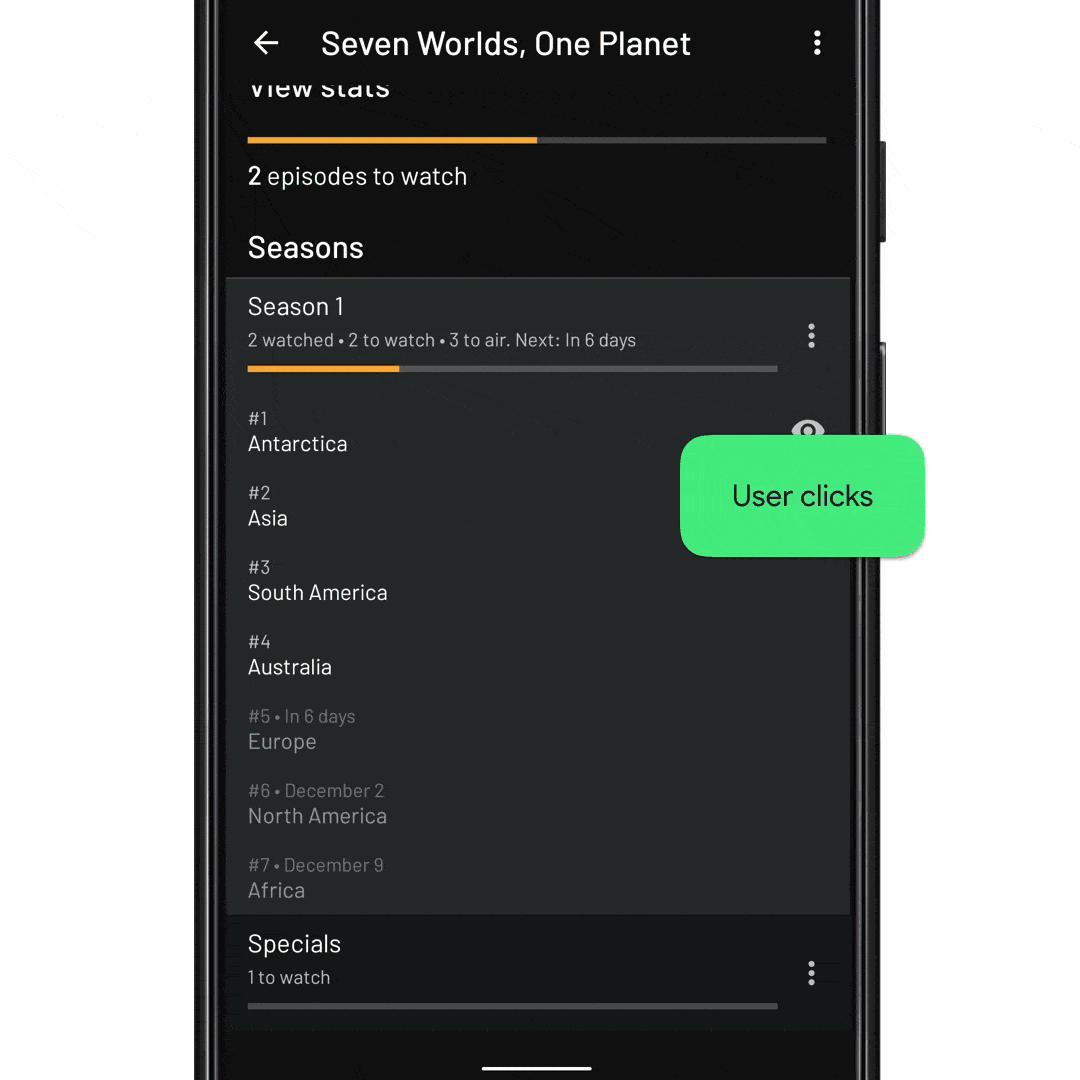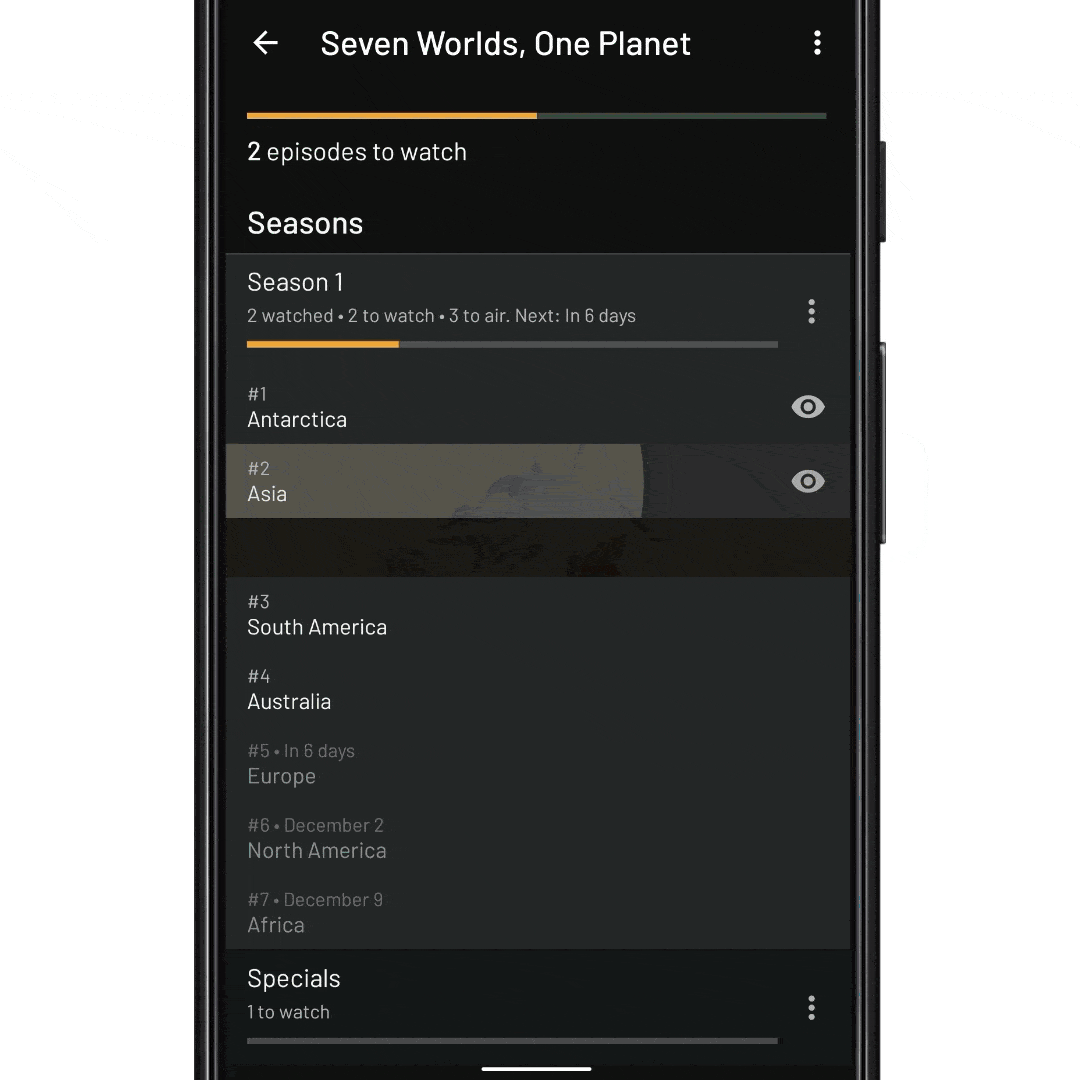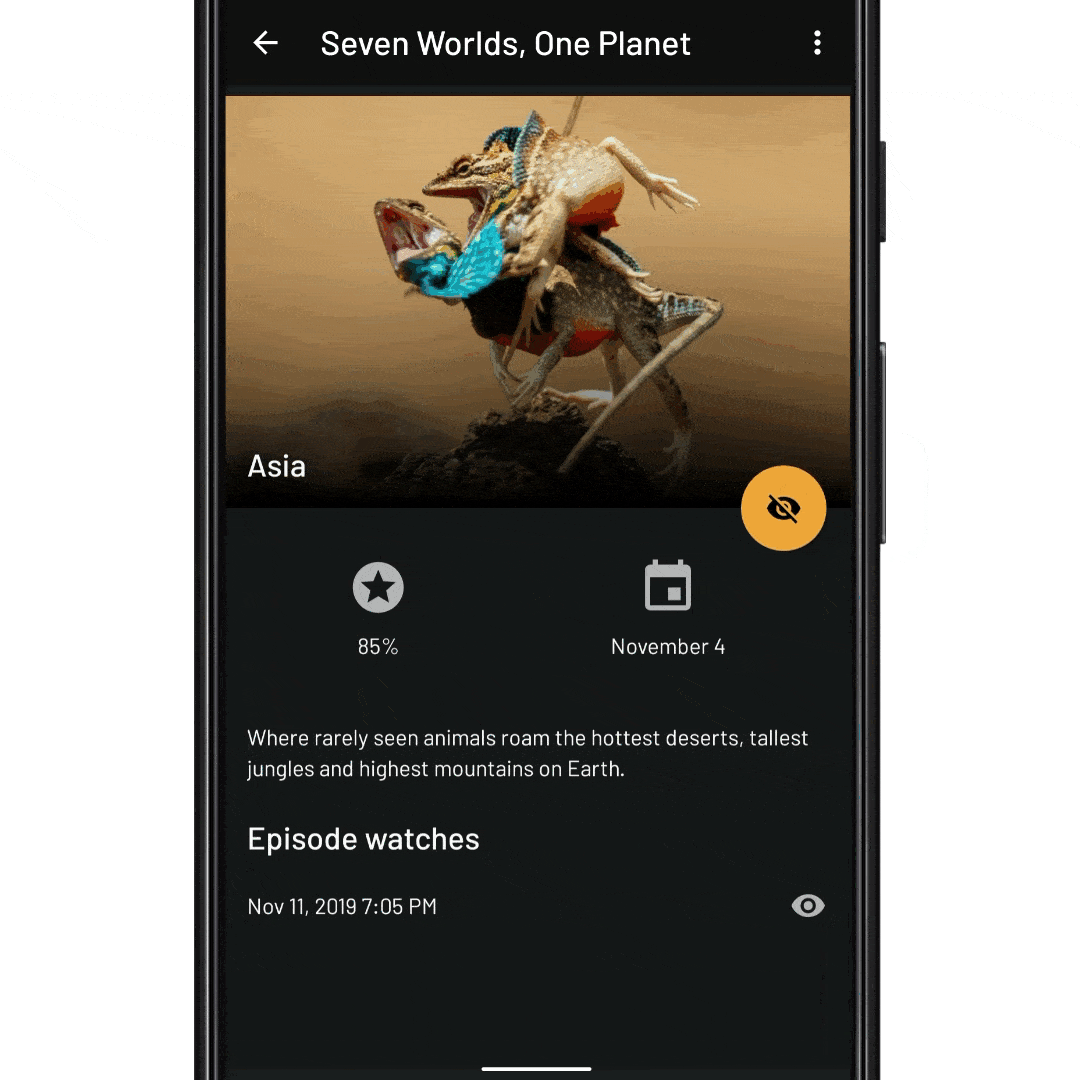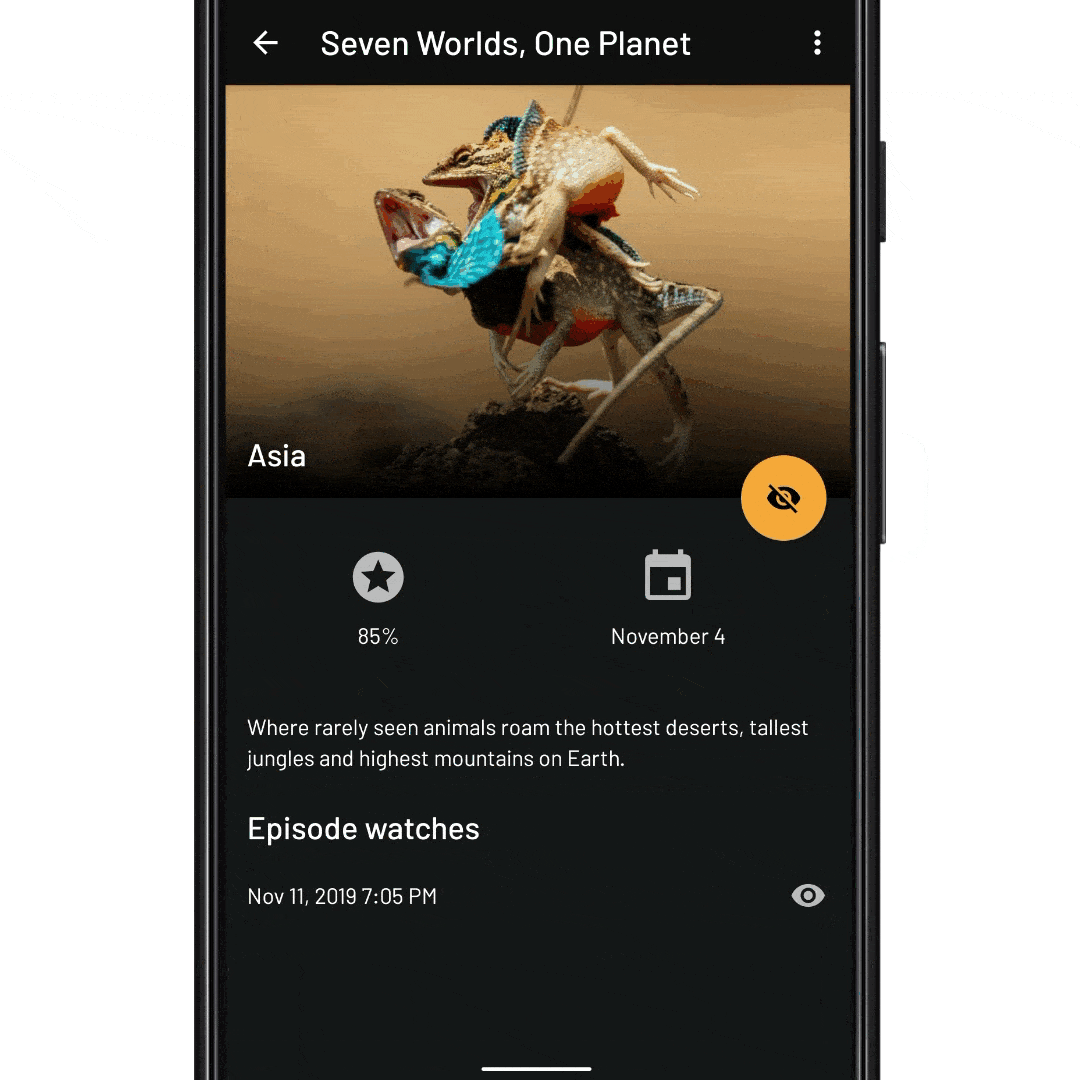
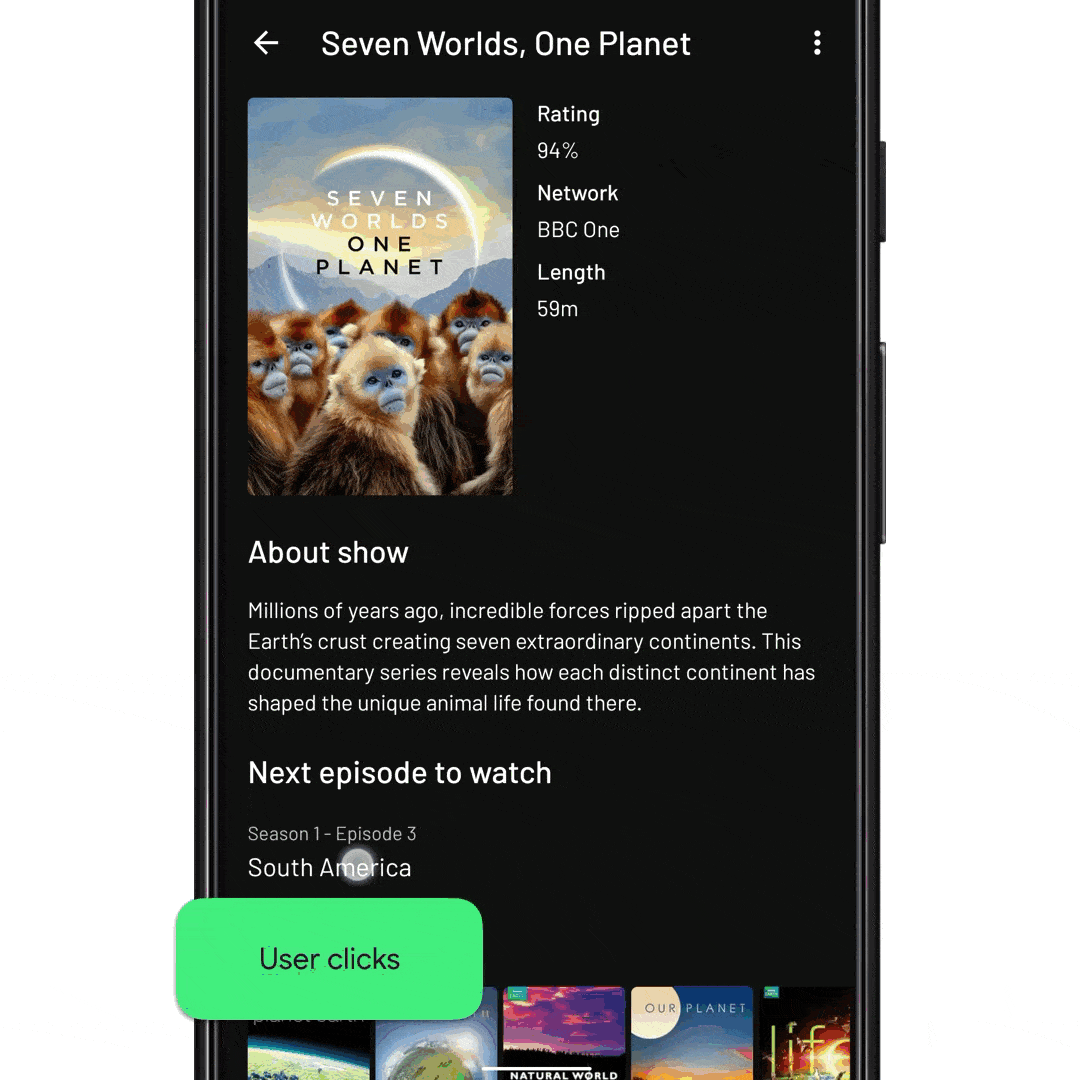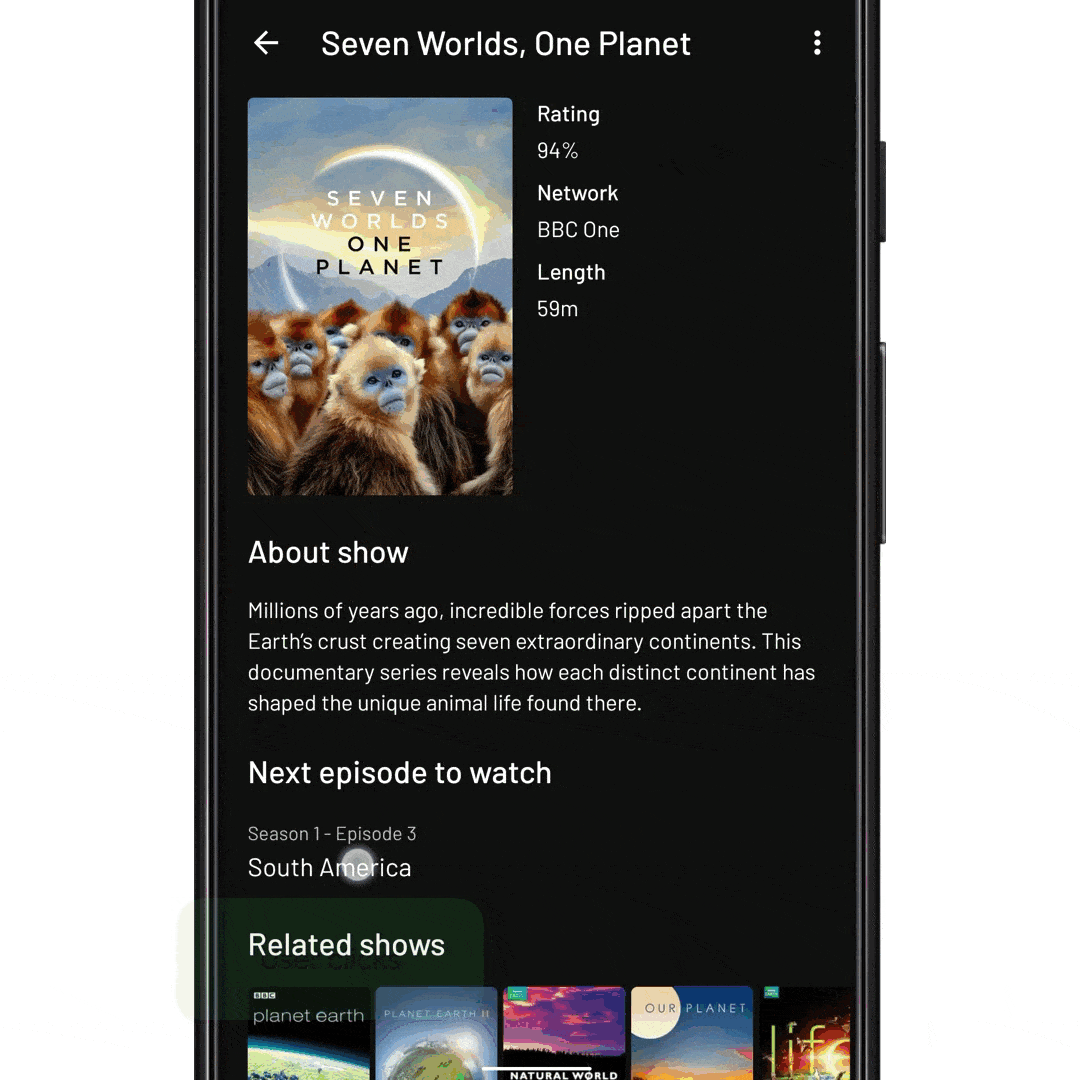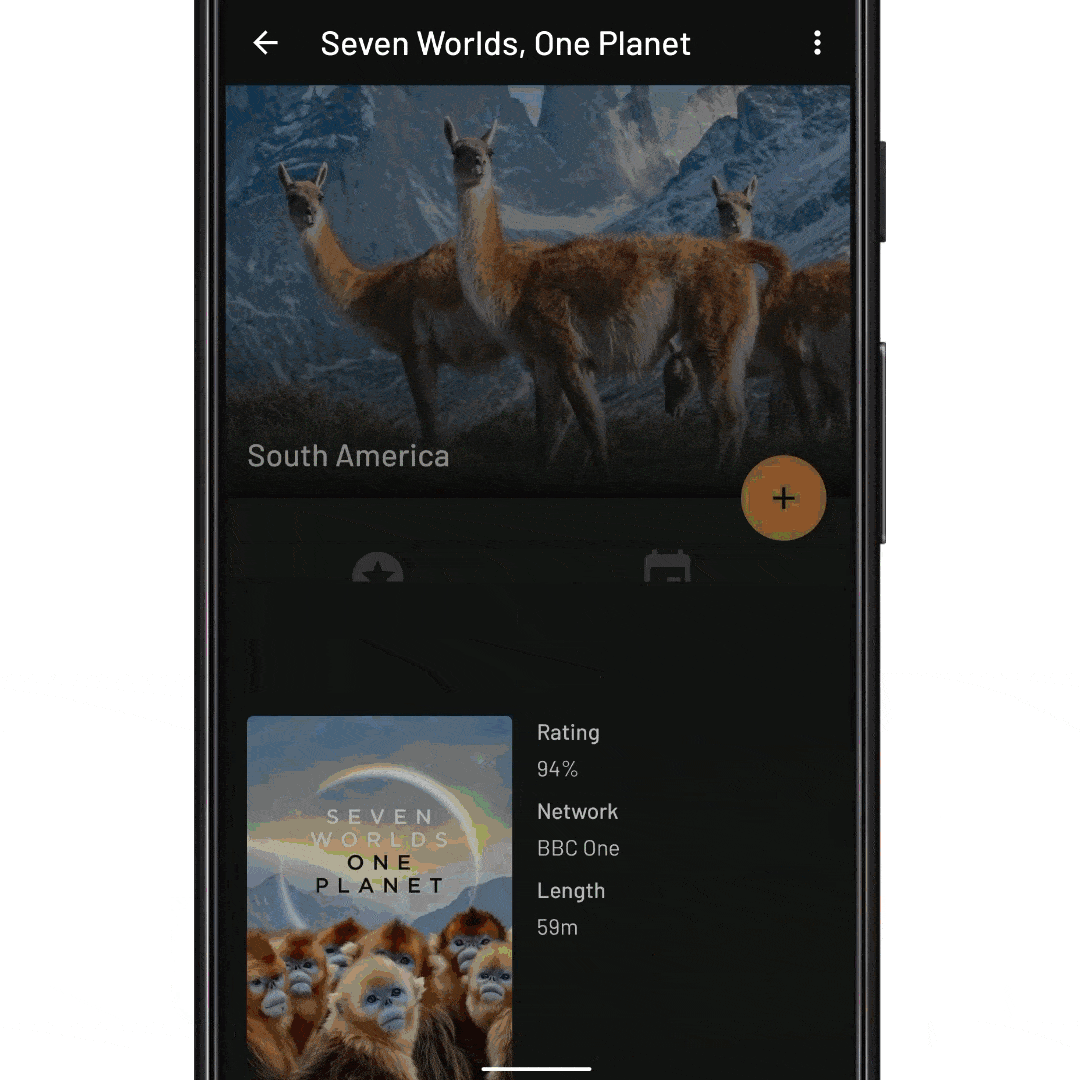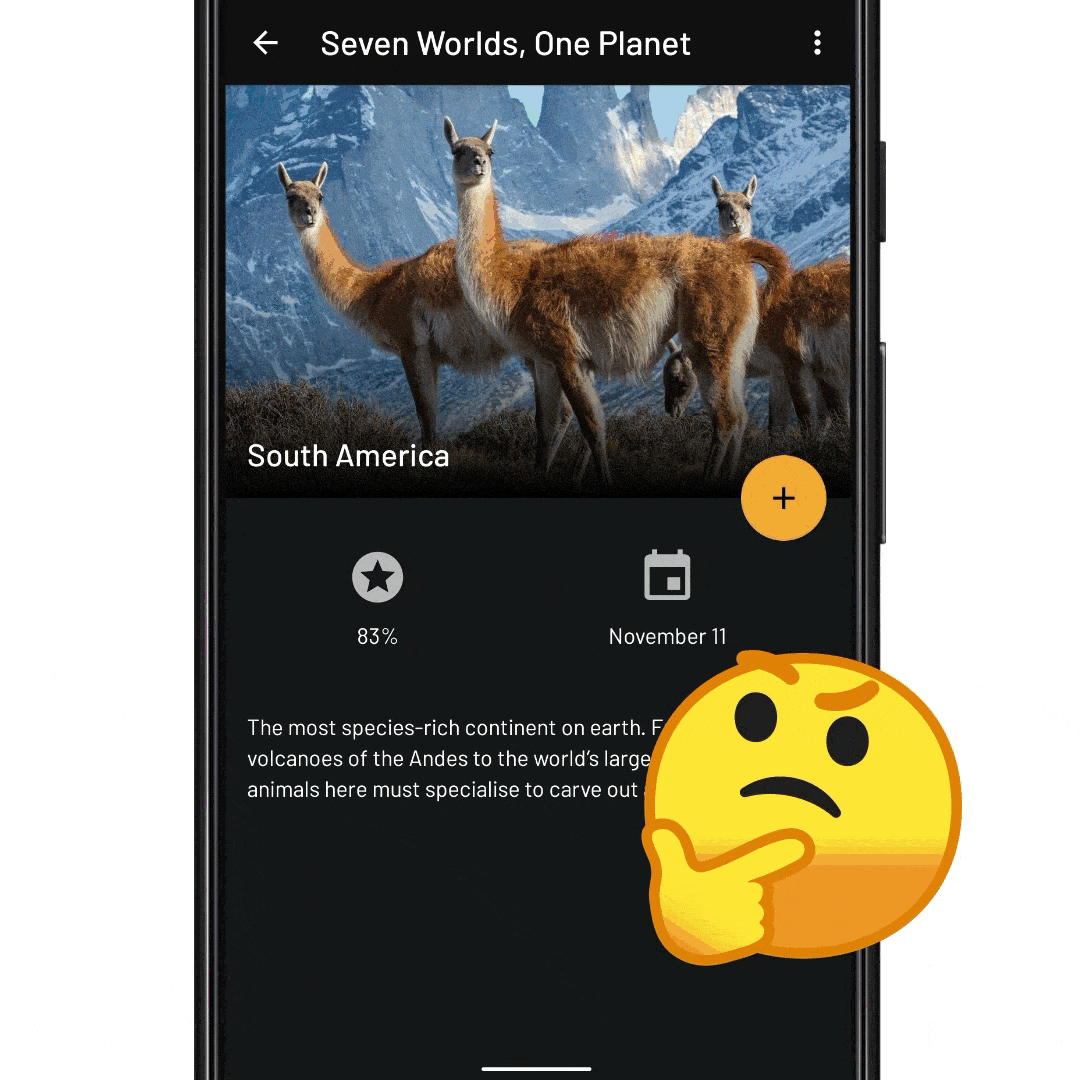
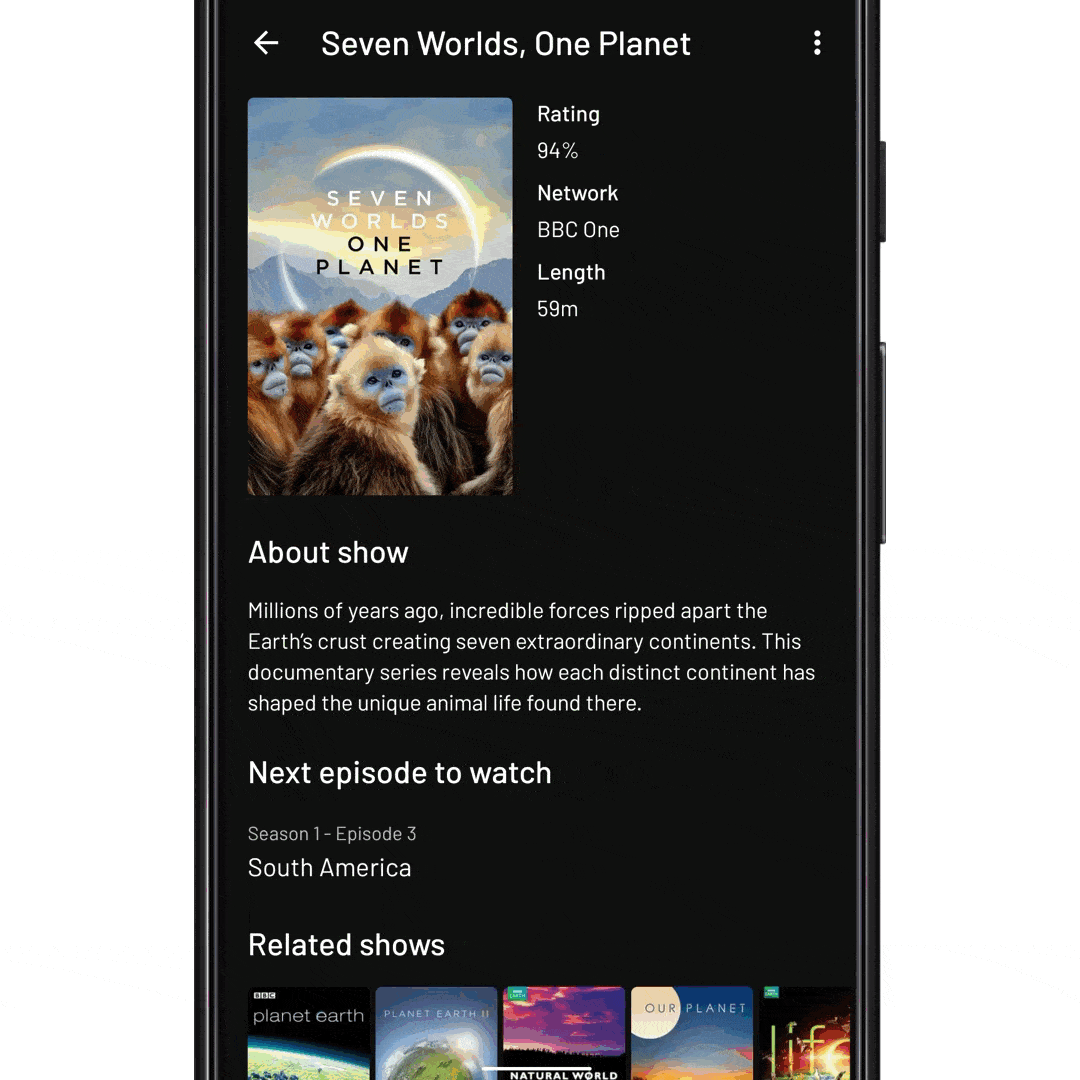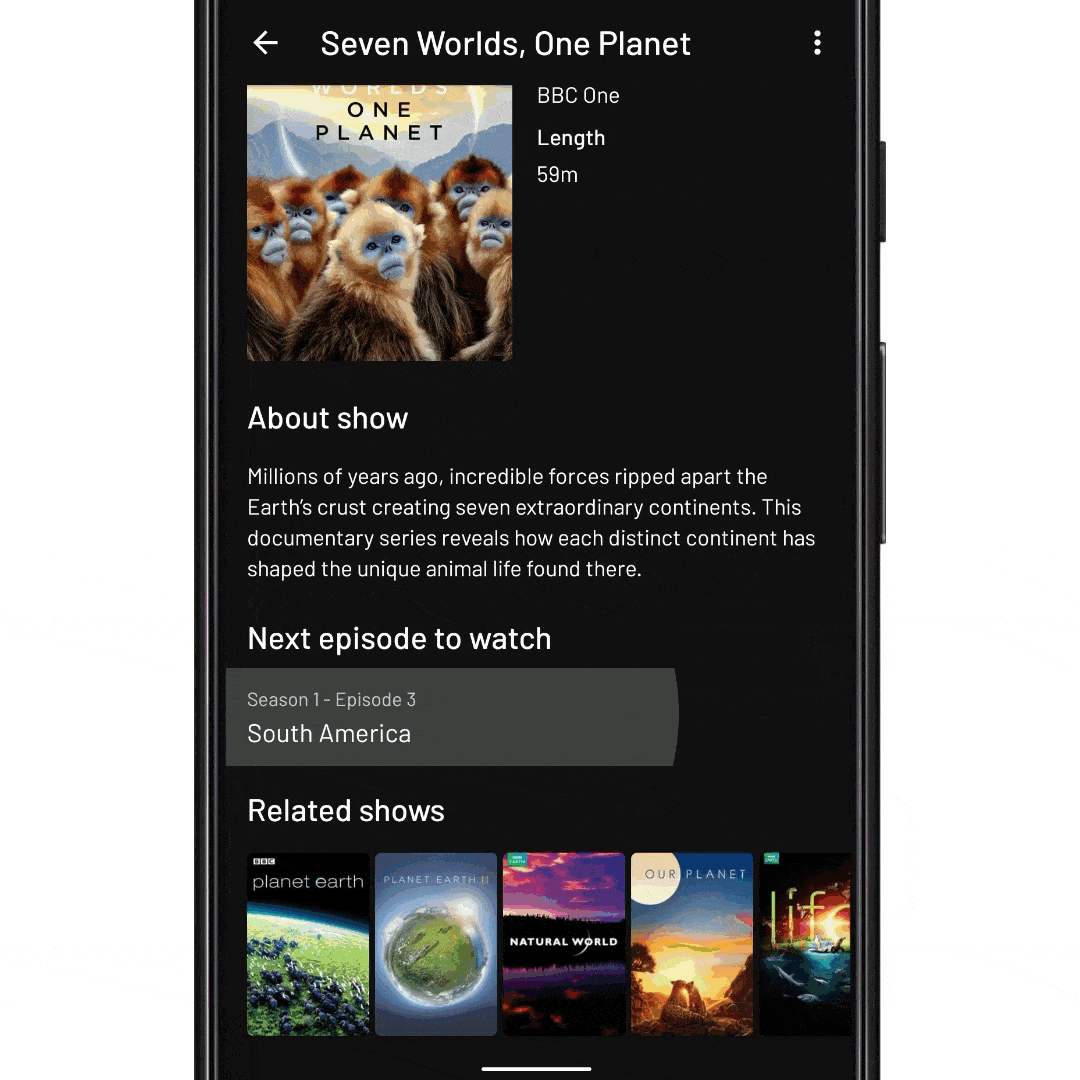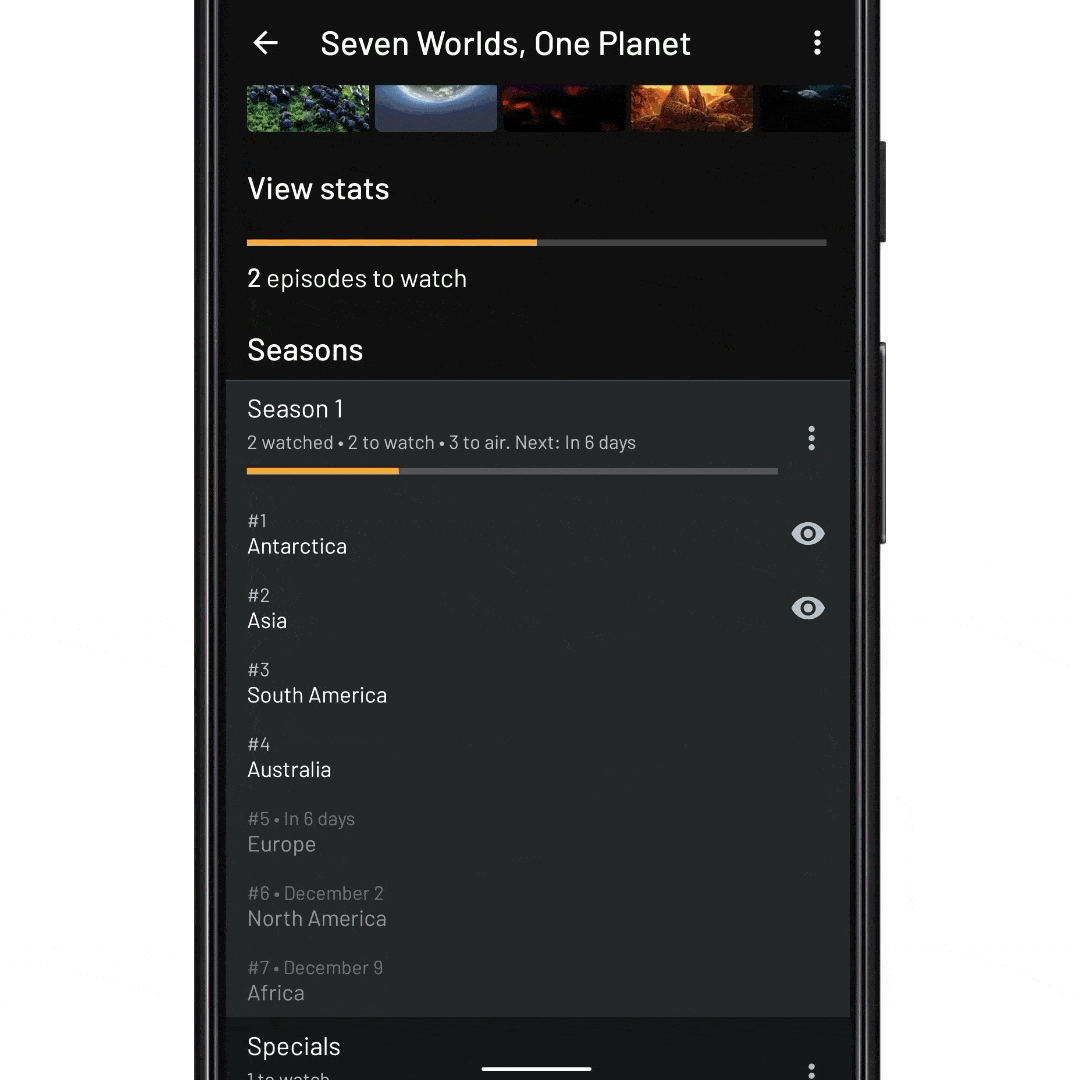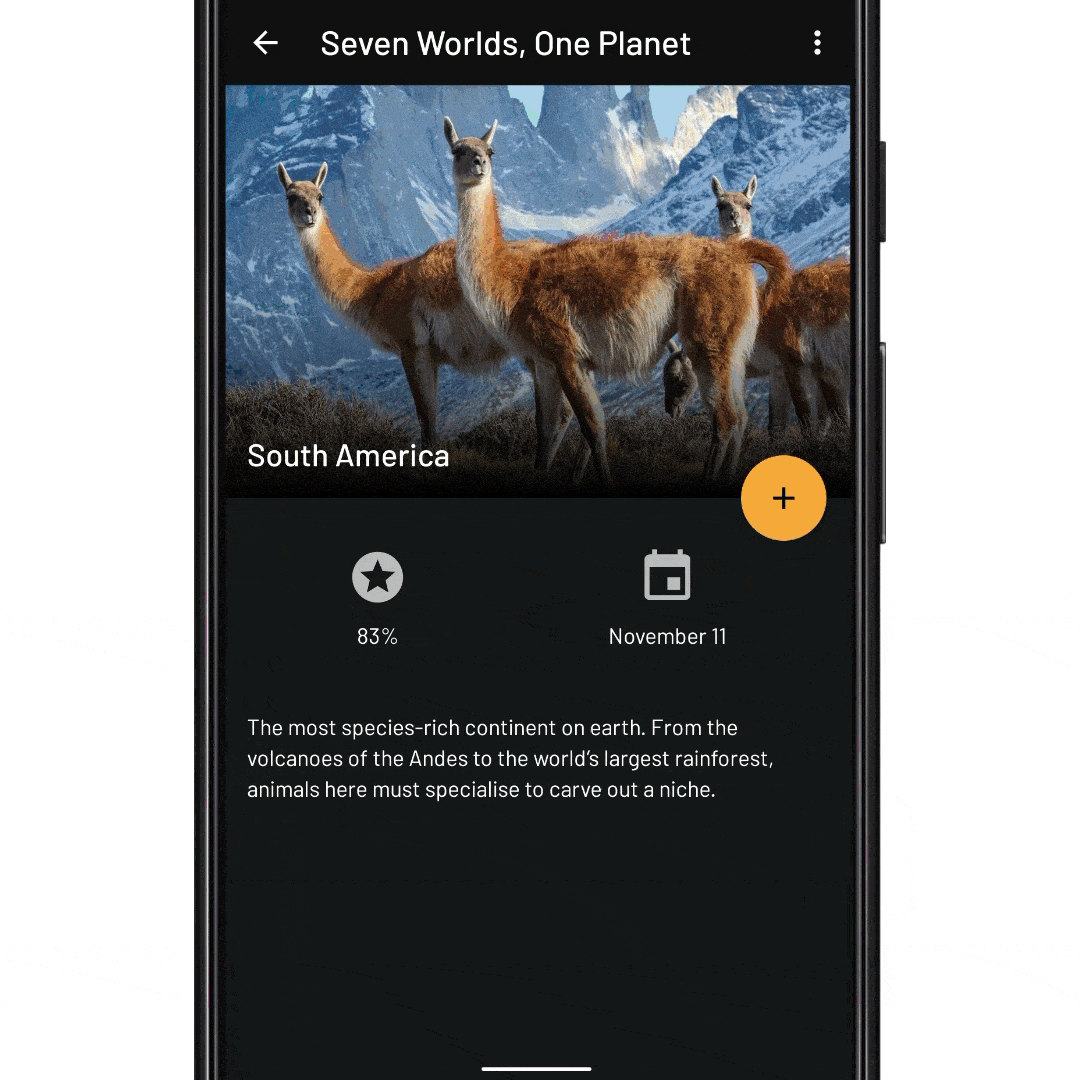
fun onEpisodeItemClicked(view: View, episode: Episode) { // Tell InboxRecyclerView to expand the episode item. // We pass it the ID of the item to expand recyclerView.expandItem(episode.id) }
fun onNextEpisodeToWatchItemClick(view: View, nextEpisodeToWatch: Episode) { // Tell the ViewModel to include the season’s episodes in the // RecyclerView data set. This will trigger a database fetch, and update // the view state viewModel.expandSeason(nextEpisodeToWatch.seasonId) // Scroll the RecyclerView so that the episode is displayed recyclerView.scrollToItemId(nextEpisodeToWatch.id) // Expand the item like before recyclerView.expandItem(nextEpisodeToWatch.id) }
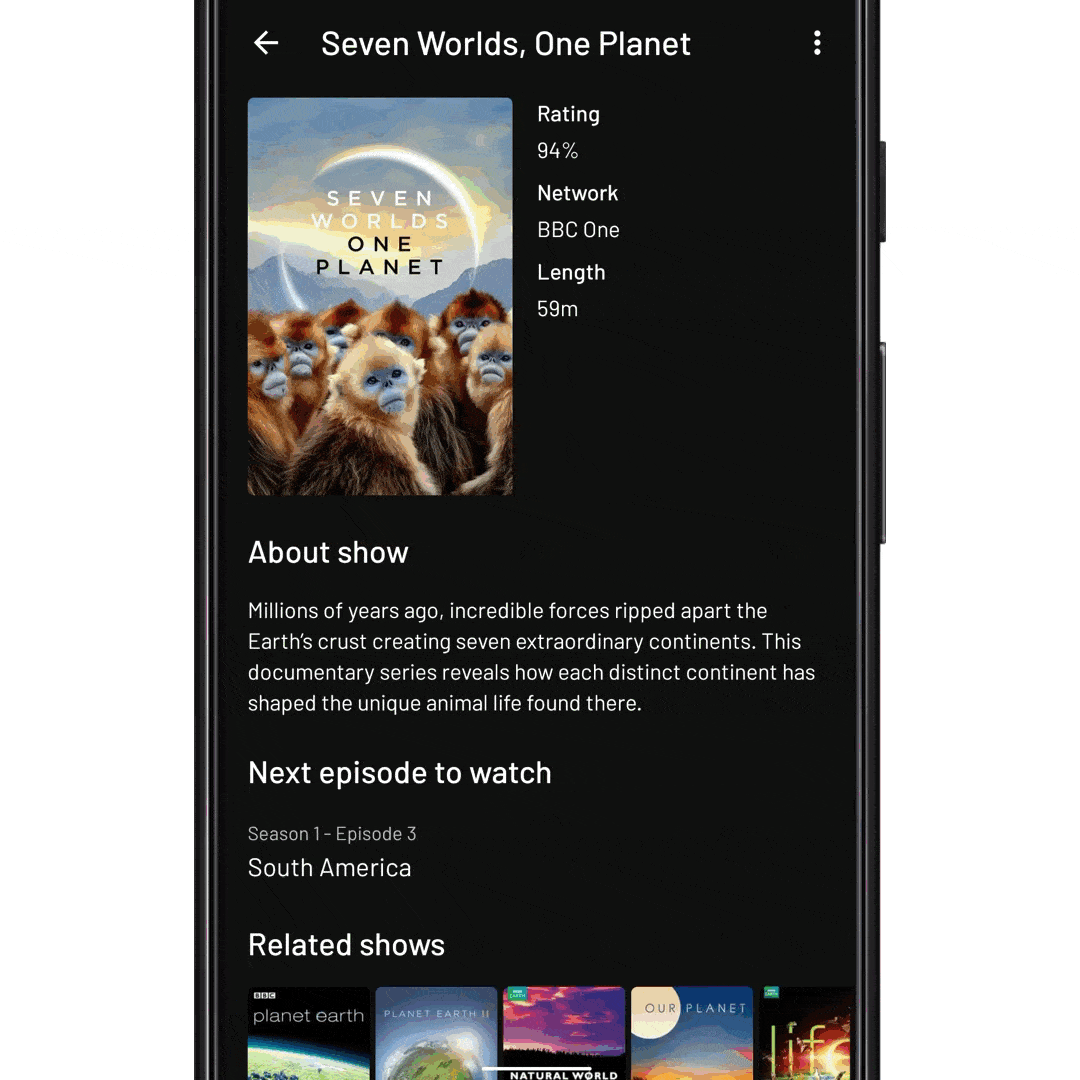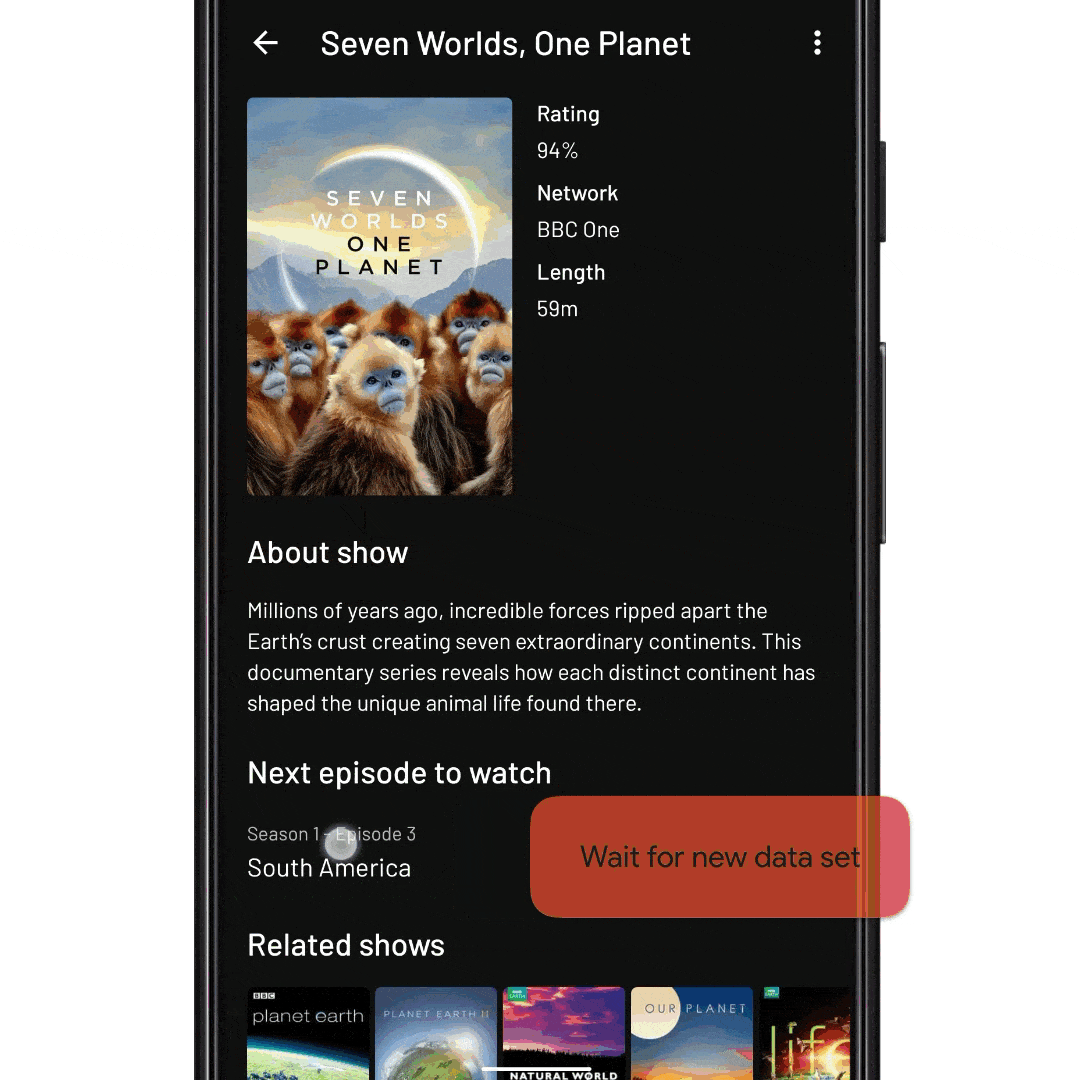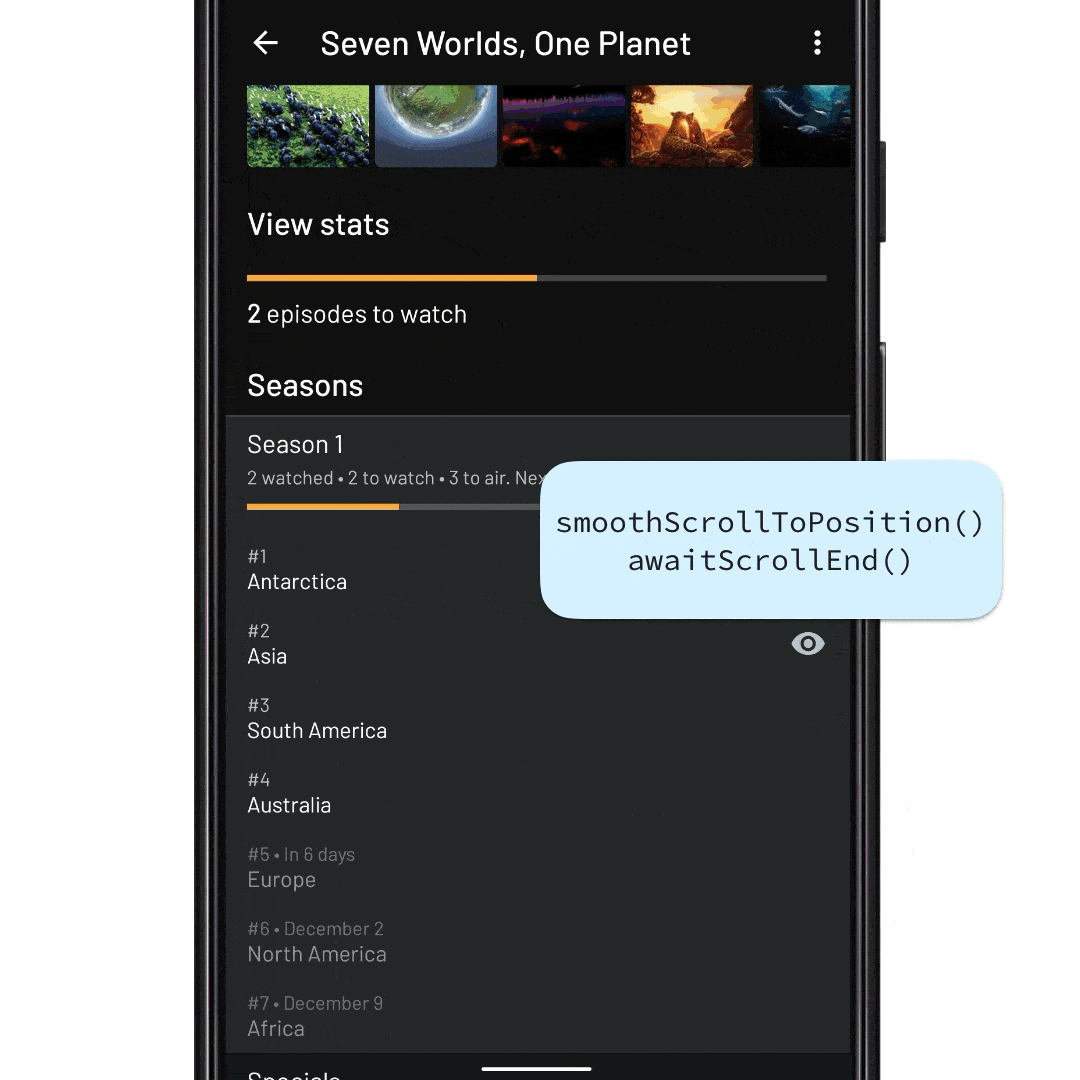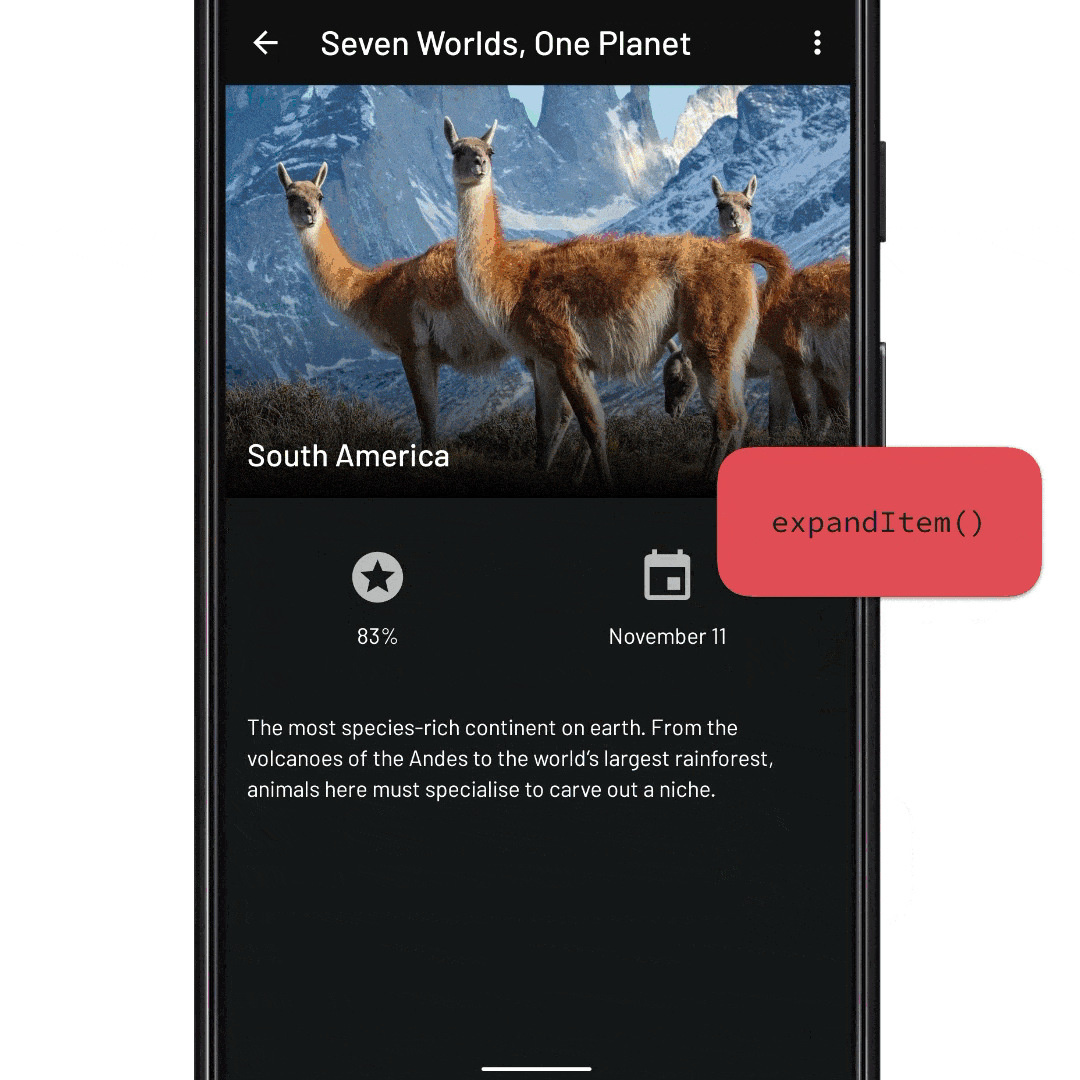
fun onNextEpisodeToWatchItemClick(view: View, nextEpisodeToWatch: Episode) { // Tell the ViewModel to include the season’s episodes in the // RecyclerView data set. This will trigger a database fetch viewModel.expandSeason(nextEpisodeToWatch.seasonId) // TODO wait for new state dispatch from the ViewModel // TODO wait for RecyclerView adapter to diff new data set // TODO wait for RecyclerView to layout any new items // Scroll the RecyclerView so that the episode is displayed recyclerView.scrollToItemId(nextEpisodeToWatch.id) // TODO wait for RecyclerView scroller to finish // Expand the item like before recyclerView.expandItem(nextEpisodeToWatch.id) }
fun expandEpisodeItem(itemId: Long) { recyclerView.expandItem(itemId) } fun scrollToEpisodeItem(position: Int) { recyclerView.smoothScrollToPosition(position) // Add a scroll listener, and wait for the RV to be become idle recyclerView.addOnScrollListener(object : OnScrollListener() { override fun onScrollStateChanged(recyclerView: RecyclerView, newState: Int) { if (newState == RecyclerView.SCROLL_STATE_IDLE) { expandEpisodeItem(episode.id) } } }) } fun waitForEpisodeItemInAdapter() { // We need to wait for the adapter to contain the item id val position = adapter.findItemIdPosition(itemId) if (position != RecyclerView.NO_POSITION) { // The item ID is in the adapter, now we can scroll to it scrollToEpisodeItem(itemId)) } else { // Otherwise we wait for new items to be added to the adapter and try again adapter.registerAdapterDataObserver(object : AdapterDataObserver() { override fun onItemRangeInserted(positionStart: Int, itemCount: Int) { waitForEpisodeItemInAdapter() } }) } } // And tell the ViewModel to give us the expanded season data set viewModel.expandSeason(nextEpisodeToWatch.seasonId) // Now need to wait for the new data waitForEpisodeItemInAdapter()
viewLifecycleOwner.lifecycleScope.launch { // await until the adapter contains the episode item ID adapter.awaitItemIdExists(episode.id) // Find the position of the season item val seasonItemPosition = adapter.findItemIdPosition(episode.seasonId) // Scroll the RecyclerView so that the season item is at the // top of the viewport recyclerView.smoothScrollToPosition(seasonItemPosition) // ...and await that scroll to finish recyclerView.awaitScrollEnd() // Finally, expand the episode item to show the episode details recyclerView.expandItem(episode.id) }
/** * Wait for the transition to complete so that the given [transitionId] is fully displayed. * * @param transitionId The transition set to await the completion of * @param timeout Timeout for the transition to take place. Defaults to 5 seconds. */ suspend fun MultiListenerMotionLayout.awaitTransitionComplete(transitionId: Int, timeout: Long = 5000L) { // If we're already at the specified state, return now if (currentState == transitionId) return var listener: MotionLayout.TransitionListener? = null try { withTimeout(timeout) { suspendCancellableCoroutine<Unit> { continuation -> val l = object : TransitionAdapter() { override fun onTransitionCompleted(motionLayout: MotionLayout, currentId: Int) { if (currentId == transitionId) { removeTransitionListener(this) continuation.resume(Unit) } } } // If the coroutine is cancelled, remove the listener continuation.invokeOnCancellation { removeTransitionListener(l) } // And finally add the listener addTransitionListener(l) listener = l } } } catch (tex: TimeoutCancellationException) { // Transition didn't happen in time. Remove our listener and throw a cancellation // exception to let the coroutine know listener?.let(::removeTransitionListener) throw CancellationException("Transition to state with id: $transitionId did not" + " complete in timeout.", tex) } }
// Make sure that the season is expanded, with the episode attached viewModel.expandSeason(nextEpisodeToWatch.seasonId)
// 1. Wait for new data dispatch // 2. Wait for RecyclerView adapter to diff new data set
// Scroll the RecyclerView so that the episode is displayed recyclerView.scrollToItemId(nextEpisodeToWatch.id)
/** * Await an item in the data set with the given [itemId], and return its adapter position. */ suspend fun <VH : RecyclerView.ViewHolder> RecyclerView.Adapter<VH>.awaitItemIdExists(itemId: Long): Int { val currentPos = findItemIdPosition(itemId) // If the item is already in the data set, return the position now if (currentPos >= 0) return currentPos // Otherwise we register a data set observer and wait for the item ID to be added return suspendCancellableCoroutine { continuation -> val observer = object : RecyclerView.AdapterDataObserver() { override fun onItemRangeInserted(positionStart: Int, itemCount: Int) { (positionStart until positionStart + itemCount).forEach { position -> // Iterate through the new items and check if any have our itemId if (getItemId(position) == itemId) { // Remove this observer so we don't leak the coroutine unregisterAdapterDataObserver(this) // And resume the coroutine continuation.resume(position) } } } } // If the coroutine is cancelled, remove the observer continuation.invokeOnCancellation { unregisterAdapterDataObserver(observer) } // And finally register the observer registerAdapterDataObserver(observer) } }
suspend fun RecyclerView.awaitScrollEnd() { // If a smooth scroll has just been started, it won't actually start until the next // animation frame, so we'll await that first awaitAnimationFrame() // Now we can check if we're actually idle. If so, return now if (scrollState == RecyclerView.SCROLL_STATE_IDLE) return suspendCancellableCoroutine<Unit> { continuation -> continuation.invokeOnCancellation { // If the coroutine is cancelled, remove the scroll listener recyclerView.removeOnScrollListener(this) // We could also stop the scroll here if desired } addOnScrollListener(object : RecyclerView.OnScrollListener() { override fun onScrollStateChanged(recyclerView: RecyclerView, newState: Int) { if (newState == RecyclerView.SCROLL_STATE_IDLE) { // Make sure we remove the listener so we don't leak the // coroutine continuation recyclerView.removeOnScrollListener(this) // Finally, resume the coroutine continuation.resume(Unit) } } }) } }
suspend fun View.awaitAnimationFrame() = suspendCancellableCoroutine<Unit> { continuation -> val runnable = Runnable { continuation.resume(Unit) } // If the coroutine is cancelled, remove the callback continuation.invokeOnCancellation { removeCallbacks(runnable) } // And finally post the runnable postOnAnimation(runnable) }