Le organizzazioni moderne elaborano quantità di testo sempre maggiori. Sebbene alcuni compiti come l'annotazione legale debbano essere eseguiti da professionisti esperti con anni di esperienza nel settore, altri processi richiedono tipi più semplici di ordinamento, elaborazione e analisi, nei quali il machine learning può essere spesso d'aiuto.
La categorizzazione del contenuto del testo è un'attività comune di machine learning, in genere denominata "classificazione dei contenuti", che include tutti i tipi di applicazioni, dall'analisi del sentiment nella recensione del prodotto di consumo in un sito di vendita al dettaglio al routing delle richieste di assistenza clienti all'appropriato agente di supporto.
AutoML Natural Language aiuta gli sviluppatori e i data scientist a creare modelli di classificazione dei contenuti personalizzati, senza programmazione. L'
API Natural Language di Google Cloud aiuta a classificare il testo immesso in una serie di
categorie predefinite. Se queste categorie sono adatte per te, l'API è un ottimo punto di partenza, ma se hai bisogno di categorie personalizzate, l'opzione migliore è molto probabilmente creare un modello con AutoML Natural Language.
In questo post ti guideremo attraverso l'intero processo di utilizzo di AutoML Natural Language. Utilizzeremo il
set di dati 20 Newsgroups, che consiste di circa 20.000 post equamente divisi in 20 newsgroup diversi ed è frequentemente utilizzato per la classificazione dei contenuti e le attività di clustering.
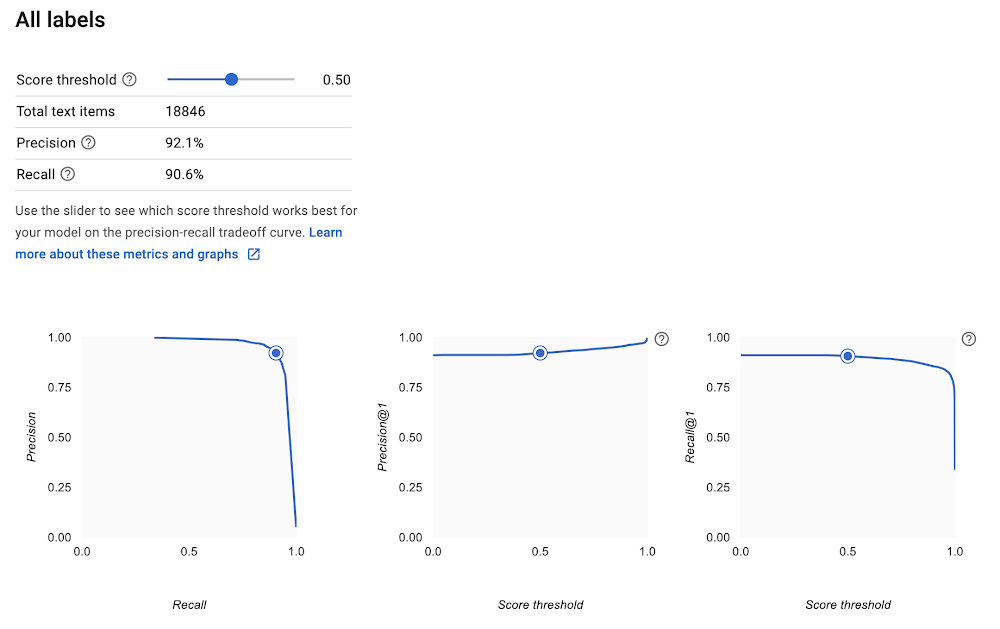
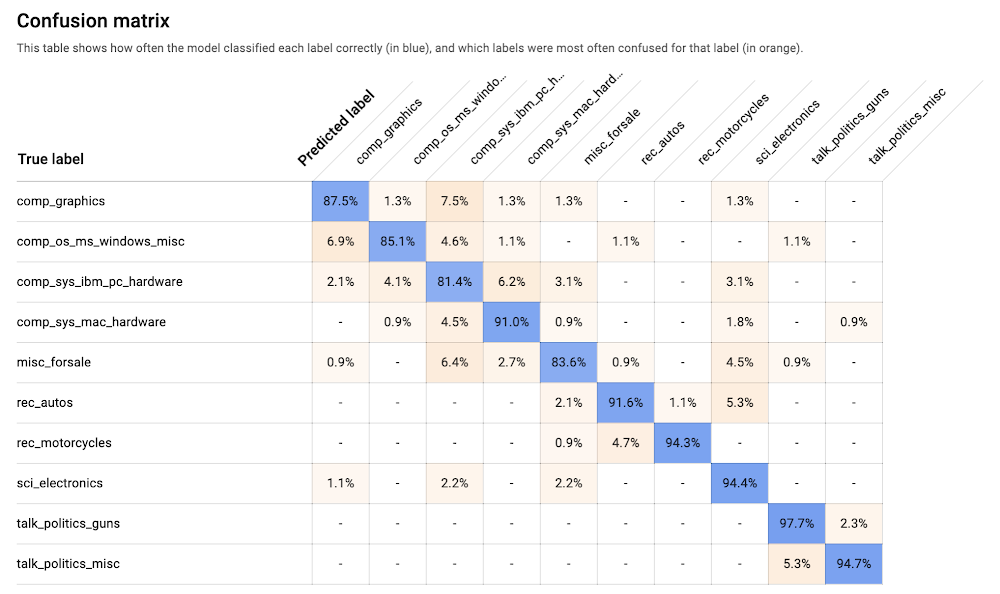
Come vedrai, questo può essere un esercizio divertente e complicato, dal momento che i post in genere usano un linguaggio informale e a volte vanno fuori tema. Inoltre, alcuni dei newsgroup che useremo del set di dati si sovrappongono un po'; ad esempio, due gruppi diversi tra loro trattano l'argomento dell'hardware per PC e Mac.
Preparazione dei datiIniziamo innanzitutto scaricando i dati. Ho incluso un link a un notebook Jupyter che eseguirà il download del set di dati raw per poi convertirlo nel formato CSV previsto da AutoML Natural Language. AutoML Natural Language cerca il testo o un URL nella prima colonna e l'etichetta nella seconda colonna. Nel nostro esempio, assegniamo un'etichetta a ciascun campione, sebbene AutoML Natural Language supporti anche più etichette.
Per scaricare i dati, puoi semplicemente eseguire il notebook nell'ambiente di
Google Colab ospitato, oppure puoi trovare
il codice sorgente su GitHub.
Importazione dei datiOra siamo pronti per accedere alla
UI di AutoML Natural Language. Iniziamo creando un nuovo set di dati facendo clic sul pulsante New Dataset (Nuovo set di dati). Crea un nome come
twenty_newsgroups e carica il CSV scaricato nel passaggio precedente.