Oggi sempre più applicazioni vengono distribuite in container su Kubernetes, al punto che alcuni definiscono Kubernetes il Linux del cloud. Nonostante tutta questa crescita al livello applicativo, il livello dei dati non ha riscosso lo stesso consenso con la containerizzazione. Ciò non sorprende, dal momento che i carichi di lavoro containerizzati devono intrinsecamente essere resilienti a riavvii, scalabilità orizzontale, virtualizzazione e altri vincoli. Quindi, la gestione di aspetti come lo stato (il database), la disponibilità ad altri livelli dell'applicazione e la ridondanza per un database possono avere requisiti molto specifici. Ciò rende difficile eseguire un database in un ambiente distribuito.
Tuttavia, il livello dei dati sta ricevendo maggiori attenzioni, giacché molti sviluppatori vogliono trattare l'infrastruttura dei dati allo stesso modo degli stack di applicazioni. Gli operatori desiderano utilizzare gli stessi strumenti per database e applicazioni e ottenere gli stessi vantaggi offerti dal livello delle applicazioni nel livello dei dati: spin-up rapido e ripetibilità nei vari ambienti. In questo blog, analizzeremo quando e quali tipi di database possono essere eseguiti efficacemente su Kubernetes.
Prima di approfondire le considerazioni relative all'esecuzione di un database su Kubernetes, esaminiamo brevemente le nostre opzioni per l'esecuzione dei database su
Google Cloud Platform (GCP) e quali sono i loro utilizzi ideali.
- Database completamente gestiti. Compresi Cloud Spanner, Cloud Bigtable e Cloud SQL, tra gli altri. Questa è l'opzione "low-ops", poiché Google Cloud gestisce molte delle attività di manutenzione, come backup, applicazione di patch e scalabilità. Come sviluppatore o operatore, non devi preoccupartene. Devi solo creare un database, realizzare la tua app e lasciare che Google Cloud si occupi della scalabilità al posto tuo. Ciò significa anche che potresti non avere accesso alla versione esatta di un database, a un'estensione o all'esatta configurazione del database che desideri.
- Fai-da-te su una VM. Questa può essere considerata l'opzione "full-ops", in cui ti assumi la piena responsabilità della creazione del database, della scalabilità, della gestione dell'affidabilità, della configurazione del backup e di altro ancora. Tutto ciò può richiedere molto lavoro, ma hai a disposizione tutte le funzionalità e le configurazioni del database.
- Esegui su Kubernetes. L'esecuzione di un database su Kubernetes è più simile all'opzione full-ops, ma offre vantaggi in termini dell'automazione fornita da Kubernetes per mantenere l'applicazione del database in esecuzione. Detto questo, è importante ricordare che i pod (i container delle applicazioni del database) sono transitori, quindi la probabilità di riavvio o failover delle applicazioni del database è più elevata. Inoltre, alcune delle attività amministrative più specifiche del database (backup, scalabilità, tuning ecc.) sono diverse a causa delle astrazioni aggiunte associate alla containerizzazione.
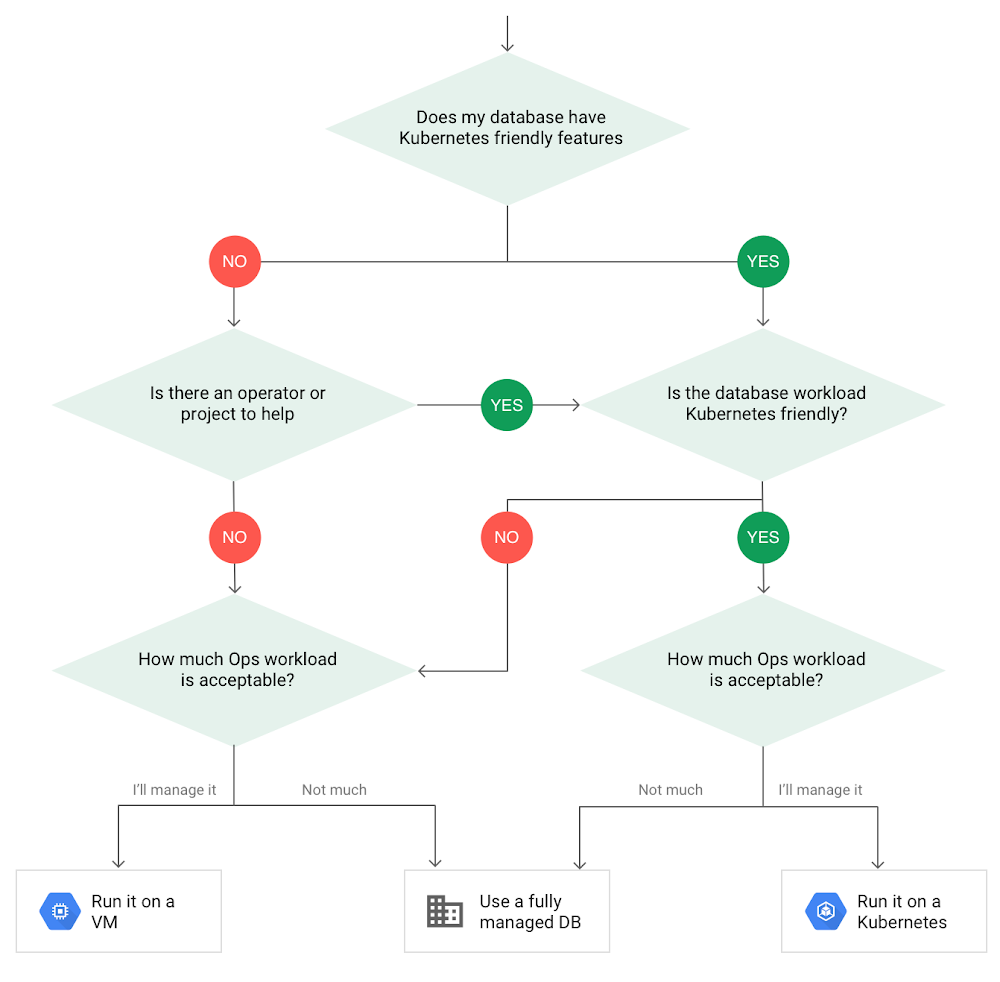
Suggerimenti per l'esecuzione del database su KubernetesQuando scegli Kubernetes, pensa a quale database eseguirai e quanto sarà efficace questo approccio, considerati i pro e contro discussi in precedenza. Poiché i pod sono transitori, la probabilità di eventi di failover è superiore a quella di un database tradizionalmente ospitato o completamente gestito. Sarà più semplice eseguire un database su Kubernetes se include concetti come partizionamento orizzontale, elezioni di failover e replica incorporate nel suo DNA (ad esempio, ElasticSearch, Cassandra o MongoDB). Alcuni progetti open source forniscono
risorse e
operatori personalizzati per facilitare la gestione del database.
Quindi, considera la funzione che il database sta eseguendo nel contesto della tua applicazione e del tuo business. I database che memorizzano più livelli transitori e di caching sono soluzioni migliori per Kubernetes. I livelli di dati di quel tipo in genere hanno una maggiore resilienza incorporata nelle applicazioni, rendendo l'esperienza complessiva migliore.
Infine, assicurati di aver compreso le modalità di replica disponibili nel database. Le modalità di replica asincrona lasciano spazio alla perdita di dati, poiché il commit delle transazioni potrebbe essere eseguito al database primario ma non ai database secondari. Quindi, cerca di capire se potresti incorrere in una perdita di dati e in che misura ciò sarebbe accettabile nel contesto della tua applicazione.
Dopo aver valutato tutte queste opzioni, ti ritroverai con un albero decisionale simile a questo: