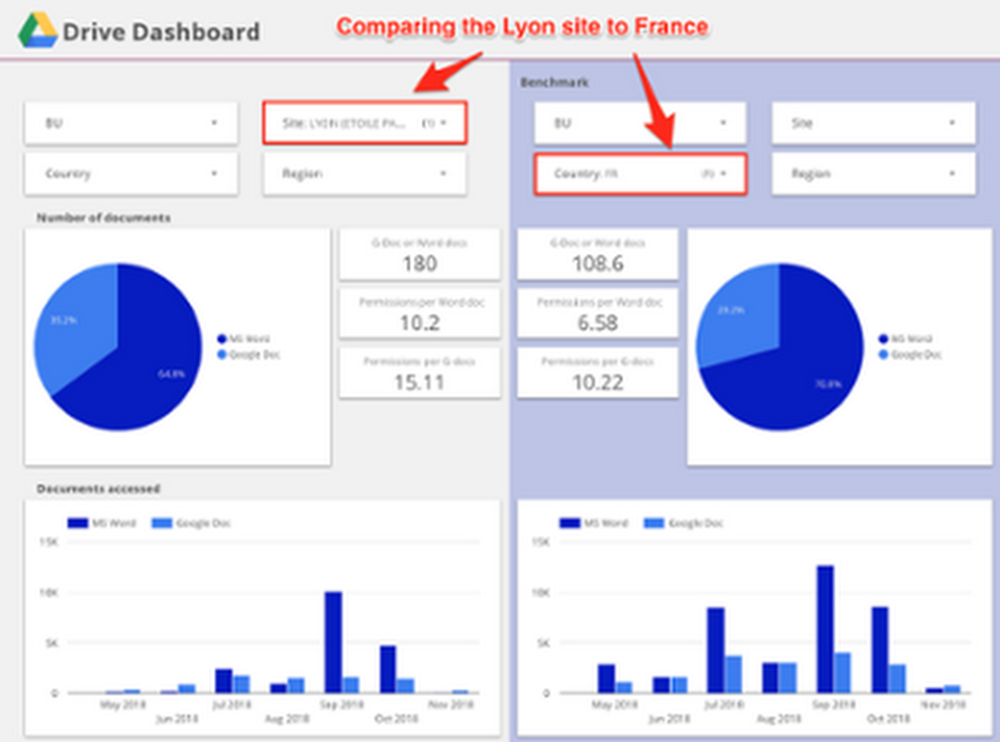
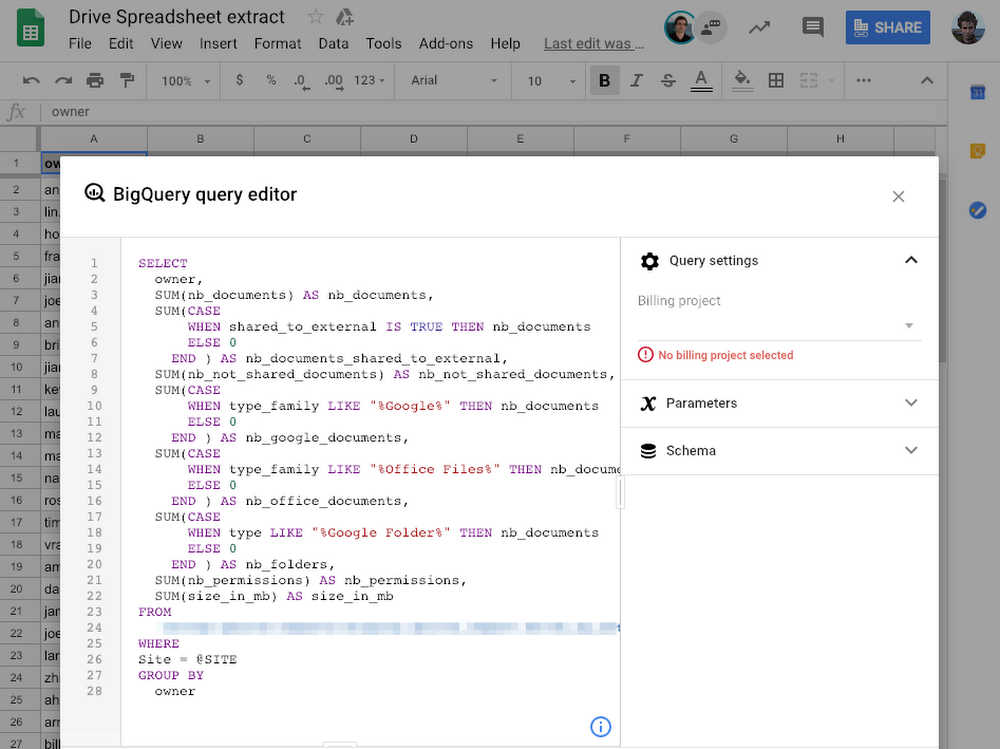
Ecco come è strutturata l'architettura ad alto livello: estraiamo i dati dalle API G Suite utilizzando App Engine, li archiviamo in Google Cloud Storage, li trasformiamo in Cloud Dataflow e li archiviamo in BigQuery per ulteriori analisi. Quindi usiamo Data Studio per la visualizzazione. Andiamo a vedere ciascuno di questi componenti.
Estrazione dei dati
Il primo passo per creare una soluzione come questa è estrarre i dati. Ci sono due modi per farlo: le API REST e la funzione BigQuery Export.
API REST
G Suite offre un numero elevato di API REST che consentono di eseguire query sui metadati dei servizi, come i documenti archiviati in Google Drive e i log di attività. In questo caso, abbiamo sviluppato un modulo di estrazione su App Engine. App Engine è eccezionale perché è completamente serverless e può essere scalato senza dover modificare la configurazione, la capacità di provisioning o gestire il bilanciamento del carico.
Esistono numerose API da cui si possono estrarre i dati e ci sono due tipi di estrazioni: snapshot dello stato corrente e log di attività. Gli snapshot vengono estratti dalle API Directory, Drive o Groups Settings. L'estrazione della directory archivia un elenco di utenti in BigQuery. Per Drive, richiediamo tutti i documenti di proprietà di ciascun utente tramite la rappresentazione di un account di servizio, ossia un tipo speciale di account Google che appartiene all'applicazione anziché a un singolo utente finale. L'applicazione assume l'identità dell'account di servizio per chiamare le API di Google in modo che gli utenti non siano coinvolti direttamente. Grazie all'integrazione dell'identità tra G Suite e GCP, diventa un gioco da ragazzi.
Inoltriamo richieste all'API utilizzando Google Cloud Tasks. Ogni utente riceve i propri Task in una Task Queue, che vengono avviati al ritmo di 100 per volta. Tutte le risposte API vengono inviate al Cloud Storage. Se l'utente possiede così tanti documenti che è impossibile sfogliarli tutti nei 10 minuti concessi, il task dell'utente si aggiunge alla coda dei task. Anche quando non riescono, le estrazioni tornano in coda. Lo stato dell'estrazione viene mantenuto come contatore decrescente in Memcache, che viene aggiornato da ciascun task se ha un esito positivo. Quando il contatore raggiunge lo 0, il lavoro viene eseguito attivando i processi di backup/trasformazione.
Se hai prestato attenzione, probabilmente ti starai chiedendo cosa succederà ai Team Drive e come estrarre i dati dai documenti archiviati lì? Ottima domanda. Anche se, in qualità di amministratore, puoi ottenere l'elenco di tutti i Team Drive di un dominio, non è possibile elencare i documenti archiviati all'interno di questi Team Drive, quindi il processo è un po' complesso. Ecco come risolviamo la questione: per prima cosa elenchiamo tutti i Team Drive nel dominio. Quindi esaminiamo ciascun utente per trovare gli utenti appartenenti a ciascun Drive e poterli rappresentare con l'account di servizio e infine elenchiamo i file nel Team Drive.
Grazie alla potenza e alla flessibilità di Google Cloud Tasks, siamo stati in grado di implementare una coda di task parallela e coordinata molto facilmente, senza preoccuparci dei server, e di estrarre tutti i contenuti dei metadati di Drive di un'azienda di 35mila dipendenti in meno di 10 minuti. In effetti, il collo di bottiglia è la quota dell'API Drive.
Estrarre i log di attività è più semplice poiché provengono dall'API Report Admin, quindi non è necessario rappresentare tutti gli utenti. Essendo dati della serie temporale, li interroghiamo quotidianamente, attivati da un cronjob in App Engine che viene affidato a Task Queue.
BigQuery Export
A differenza di altri prodotti G Suite, i clienti di G Suite Enterprise possono esportare i log giornalieri di Gmail direttamente in BigQuery. Questo è un esempio della completa integrazione tra G Suite e GCP. Se esistessero possibilità di esportazione simili con altri servizi di G Suite, ignoreremmo completamente le API e implementeremmo l'intera soluzione senza scrivere una singola riga di codice (eccetto ovviamente le query SQL).
Trasformazione e archiviazione dei dati
I dati che sono stati esportati dalle API REST ora si trovano nel Cloud Storage di JSON raw e li teniamo lì per scopi di backup e archiviazione. Per l'analisi, tuttavia, dobbiamo copiarli su BigQuery. Alla fine di ogni estrazione viene inviato un messaggio a Cloud Pub/Sub a cui ci siamo abbonati utilizzando le Cloud Functions. La funzione cloud carica i dati utilizzando le API BigQuery e Cloud Storage.